How we scale an open source, multi-tenant storage engine for Postgres written in Rust
Higher storage capacity and I/O with storage sharding

We separated storage and compute with the vision of scaling Postgres in the cloud. The compute part runs on VMs and pods, autoscales on-demand and streams Postgres Write-Ahead-Log (WAL) records to the storage engine. The storage part saves the database’s historical data in a Rust-based, multi-tenant engine named Pageserver.
The initial implementation of the storage engine stored all data of a given project in the same server, which meant that it was difficult to support large datasets without engineering intervention, and that large and small databases competed for resources on the same Pageserver.
To overcome this challenge, we implemented storage sharding, which distributes a database’s data across multiple Pageservers, delivering higher storage capacity and throughput. Storage sharding is an important component to achieving Neon’s vision, as it is a stepping stone to achieve bottomless storage.
To developers, storage sharding is invisible and requires no configuration or change in how you develop or deploy your application. This article is for those interested in understanding what Neon storage sharding is, the details of its implementation, and how it allows your applications to scale.
Storage sharding on Neon
Sharding is a type of partitioning that breaks down large databases into smaller parts called shards. In Neon, storage sharding distributes data across multiple physical Pageservers.
There are several advantages to implementing sharding to Neon, including:
- Small tenants no longer share Pageservers with huge tenants that would otherwise compete unfairly for system resources.
- Storage I/O linearly scales with dataset sizes to maintain performance as datasets scale.
- Maintenance operations, such as cross-Pageserver data migrations, have a lower impact on performance, as we can move smaller pieces at a time.
Small-size databases will likely not observe any difference in performance. Larger datasets, however, can benefit from higher storage capacity and throughput. Sharding shines in the following scenarios:
- Applications that need a higher storage capacity.
- Read-intensive workloads where the working set is much larger than the Postgres buffer cache.
- Large table scans or index builds workloads that do not fit in Postgres RAM and are limited by bandwidth to stream entire datasets from storage.
How we implement storage sharding
The purpose of the Pageserver is to store and quickly reconstruct Postgres pages from the database’s history using the GetPage@LSN function. The Pageserver was built to be multi-tenant, where each tenant represents the data of a Postgres Cluster or Neon Project.
Note:
A tenant in Neon terms holds the data of a Postgres instance. When you create a Neon project in the Console, Neon assigns it a project-id (also known as a tenant-id), and the main branch-id, which is referred to as timeline-id. See Operations for more information.
In the diagram below, we show the example of a Pageserver with 2 tenants. The area of the rectangles represents the amount of data a tenant has. The bigger the surface area, the larger the dataset. Also, for simplicity, we assume that each tenant has exactly one table.
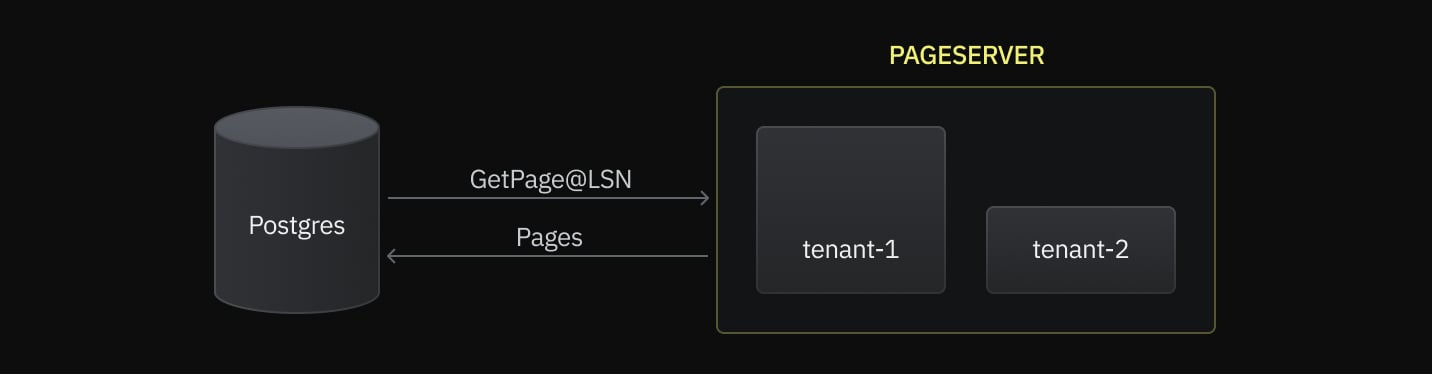
Postgres relations, such as tables or indexes, comprise a contiguous range of 8kiB blocks identified by a block number. Storage sharding divides the block number by a stripe size and hashes it to select a pseudorandom Pageserver to store that stripe.
In practice, a table smaller than the stripe size will be stored on a single Pageserver. Tables larger than stripe size * shard count will benefit from the full throughput of the system. For example, with a 256MiB (or 32k pages) stripe size and 8 shards, a table should be at least 2GiB to benefit from all pageservers’ performance. For smaller databases, the Project will run as a single shard until it grows past a threshold where Neon sharding is enabled transparently.
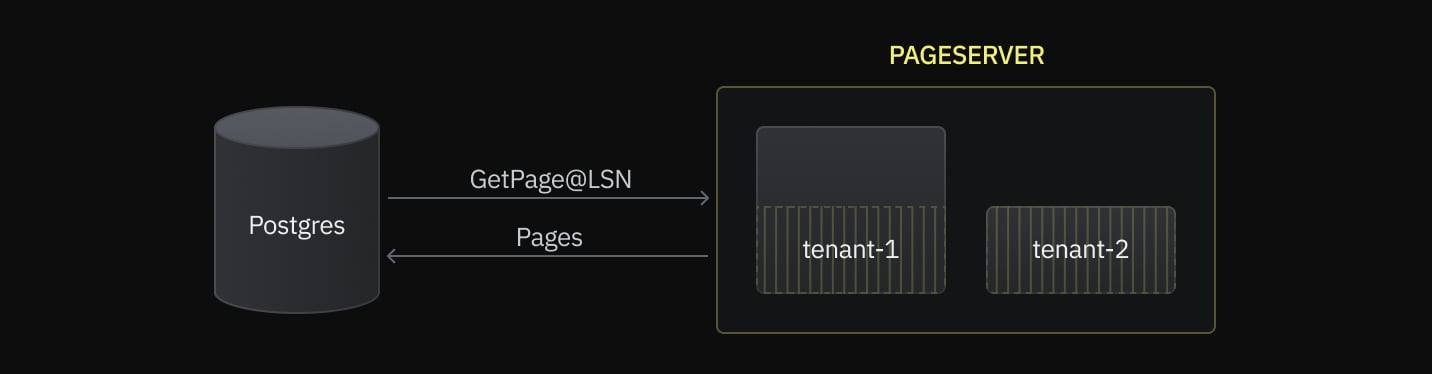
In the diagram below, the striped area represents blocks that fit the storage sharding stripe size. Tenant 2 fits the stripe size, while Tenant 1, doesn’t.
In this case, the blocks of tenant-1 will live in multiple shards. Below is an illustration of how the sharded Pageserver would look like:
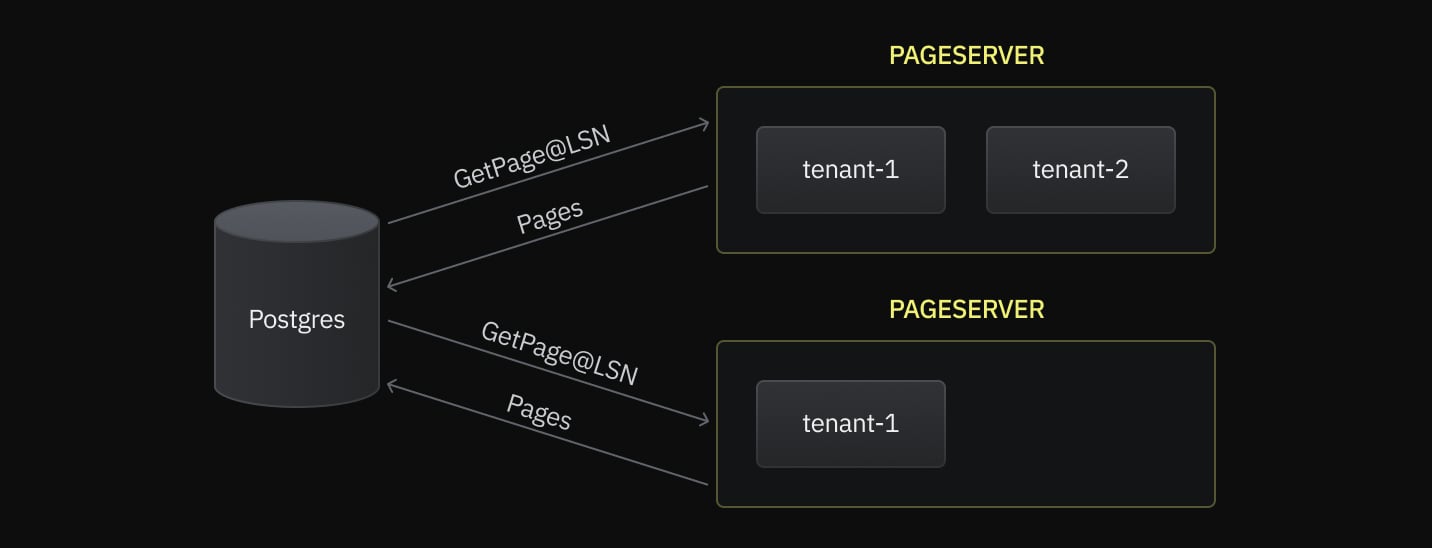
Currently, the default stripe size is 256MiB, and this cannot be changed once a tenant is split into multiple shards. As we experiment with performance, this default stripe size is likely to decrease in order to provide a smoother distribution of I/O across Pageservers.
Read & Write Paths
We’ve discussed Neon Read and Write paths in detail in the deep dive into Neon’s storage engine article. In summary, for insert, delete, and update queries, Postgres streams WAL records to a durability layer called Safekeepers, which uses the Paxos consensus algorithm. Once a quorum is reached, the WAL is sent to the Pageservers that transform it into immutable files.
For read queries, Postgres sends a page request to the Pageserver using GetPage@LSN function, which returns the desired pages.
Below is an illustration of read and write operations, colored respectively in red and green.
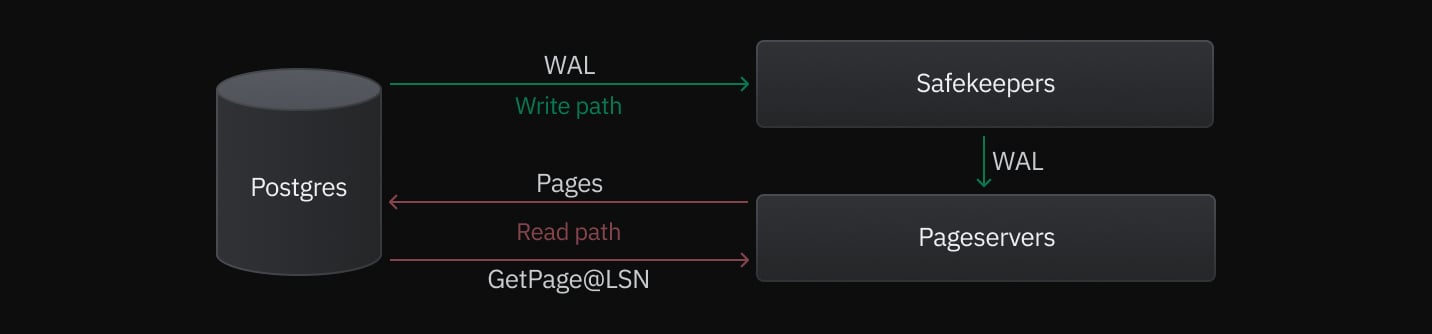
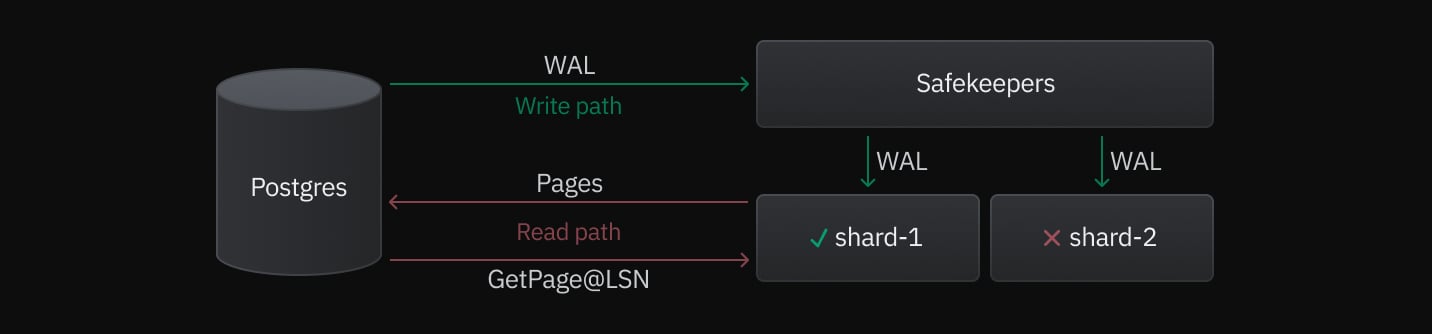
With storage sharding implemented, there were two major changes to the read and write paths:
- Shard subscription to the Safekeepers: Currently, all shards subscribe to the Safekeeper to download WAL content. They then filter it down to the pages relevant to their shard.
- Routing Pageserver requests to the right shard: For read queries, Postgres knows which page lives on which Pageserver via hashing based on the block number and the sharding configuration. Therefore, the read queries are processed without an additional proxy.
What’s next?
The current storage sharding architecture allows Neon to scale tenants to tens of terabytes of data and potentially to hundreds of terabytes in the future. However, there are a few optimizations and enhancements that we want to implement in the future, such as:
WAL fan-out
Although shard subscription to the Safekeepers doesn’t impact insert query latencies, multiple subscribers are computationally expensive. We plan to work on optimizing that by making the Safekeepers shard-aware.
Shard Splitting
The current problem is that the number of shards in a tenant is defined at creation time and cannot be changed. This causes excessive sharding for most small tenants and an upper bound on the scale for very large tenants. To address this, we will allow one shard to split its data into a number of children.
Conclusion
Storage sharding allows Neon to support databases up to 10x the current capacity. This architecture will enable even larger storage capacity in the near future and is the first step towards implementing bottomless storage.
If you have a large dataset and want to benefit from a higher throughput on Neon, contact our support team, join us in Discord, and let us know how we can help you scale your applications to millions of users.
📚 Continue reading
- A deep dive into the Neon storage engine: Neon’s custom-built storage is the core of the platform—get an overview of how it’s built.
- 1 year of autoscaling Postgres: learn how Neon can autoscale your Postgres instance without dropping connections or interrupting your queries, avoiding the need for overprovisioning or resizing manually.
- How others are using Neon: learn first-hand why others are choosing Neon. (Hint: it’s because of serverless and autoscaling, easier developer workflows due to copy-on-write branching, and Neon’s suitability for one-database-per-tenant architectures).