tl;dr> Over the past few months, a bunch of efforts by the engineering
team have greatly reduced our “cold start time” for compute resources
for idle computes that become active. This post explores the problem
and how the Neon team worked on this problem.
Background: What’s a cold start and why does it matter?
Let’s get one thing straight about this serverless thing: there are still, somewhere, in some way, servers. You, as a user of Neon don’t have to think about that, which is great, but we have to. The great benefit of Neon is that the server–we call them computes–that you connect to is ephemeral and stateless: when you’re not using it, you/we can turn it off. When the compute turns off, the cost–for everyone–of the “database” drops significantly. This is huge, and the idea is that if we can keep the compute off, except when it’s actually being used, there are a lot of workloads that become incredibly
resource efficient.
The problem is that there are still servers, someone has to “turn on the compute” (us) and while the compute is stateless in the sense that it’s easy to quickly recreate it and there’s nothing that happens in the compute that can’t be recreated, it does have some transient state, and it takes (a small amount of time.) for this to get setup.
In the history of Neon, the approach to this “startup” problem has been “let’s just make it fast:” until now, when you tried to connect to your endpoint (database) our proxy would tell our control plane “quick go start this compute,” and then the control plane would go and do this. That process takes somewhere between 3 and 6 seconds in the ideal case, but there was a lot of variance based on region and network activity, and as we add more features (extensions, etc,) it tends to get slower. “Just be fast,” at a certain point, doesn’t work anymore.
Making Cold Starts Warmer
The rest of this post is about these 3-6 seconds, and what we’ve done to be able to get a compute, up, running into about 500 milliseconds (an order of magnitude! neat,) in many cases: we think we can get it even faster and have some projects on our roadmap to keep shaving off time, though maybe not quite another order of magnitude!
Let’s be clear, allocating and configuring resources takes actual time, and there’s no black magic going on here. We’ve applied my two favorite optimization strategies: “if you have a really hard problem that you can’t solve, decide that you have a different problem,” and “the fastest way to do something is to not (need to) do it at all.” Though the applications of these strategies are pretty cool:
Only Reconfigure When you Need To
Neon has a UI that lets users make changes to their database’s configuration, for managing users, databases, roles, and extensions. These configuration options translate to an idempotent operation that starts the instance, if needed, applies changes that you make in the console to your database. This operation takes between 1 and 1.5 seconds, and it’s always safe to run, and if (for whatever reason,) your branch was out of date or sync, applying the configuration would help keep things running as you expected.
The big change here is that we don’t do this anymore: unless this is the first time you connect to your compute endpoint, there’s no need to keep track of that. Internally we track changes to configuration and use that to tell the compute if it needs to apply the configuration during start up. Most of the time, you don’t need to, and, we just saved ourselves a lot of time.
We still apply the config, just to be safe, if your compute is idle and our availability health check wakes the endpoint up. Also, most of the time, if you make a configuration-impacting change on the console, we can just tell the compute to apply the configuration changes without needing to restart your compute, which we had to do more often previously.
There are still times when we do have to apply configuration changes, but they are quite uncommon, and we’ve just saved everyone a lot of time by not doing something! Great!
Compute Pools
If the “apply configuration” changes are “don’t do something that takes a long time,” our compute pools are “choosing to solve a different tractable problem in the face of an intractable problem.”
Since its always going to take some amount of time to start a compute, we decided to (mostly) accept that the ongoing cost of keeping compute starts consistently fast across our entire fleet wasn’t something that we could do reliably: so we didn’t. Instead we’re (basically) always starting computes before anyone asks for them, and then when we get a request for a compute, we just take an “empty” compute, give it some configuration and… that’s it? You have a compute in a few hundred milliseconds.
I jest, but only a little. There were a lot of little changes that went into making this work: before our application and system we didn’t really have a concept of a “compute” separate from the endpoint, so we had to create that. Also, there’s a bunch of finesse and science in choosing at what rate we should start computes and the ideal number, location, and size of “empty computes” to maintain. We also don’t want computes to be idle in the pool for too long, both because we don’t want idle workloads that could take resources from a “real” workload, and also, we want every compute to be as up to date as possible, so we make sure to recycle computes after a period of time.
We want to make sure that when you make a request for an idle compute there’s always something there waiting for your application! Sometimes, if we don’t have a compute in the pool that suits your needs, the system gracefully falls back to creating computes in the old on-demand way: it’s slower, but it works well. We’re collecting data whenever this happens so we can work to prevent it in the future.
Having said all this, the largest part of the compute pool project was probably not the compute pools themselves, but the changes to the way computes get their configuration. In the old model, we could give the compute the config when it started, but now the compute needs to be able to get the config for itself and handle getting a new configuration once it starts. This took a little bit of elbow grease, but it also enabled the “on-demand” config application features above. While we’re just rolling out compute pools now, the new configuration system has been running for a while.
To be honest, I was expecting that the compute pools would take us from about 5 seconds to about 1.25 seconds, but in practice, it took us down to about .6 or .75 seconds, and the configuration loading changes brings us down another .2 seconds. But this is a little bit of a simplification:
The Odds and Ends
While compute pools and configuration change tracking got us (and therefore you!) a lot of time back, there were other changes that have helped: networking changes to improve the way that we configure networking for new computes, caching some internal IP addresses to avoid waiting for internal DNS routing, tactically applying concurrency, and improving how we wait for computes to become active, and, of course, a little bit of good old fashion optimization of some particularly hot code paths.
The Road from Here
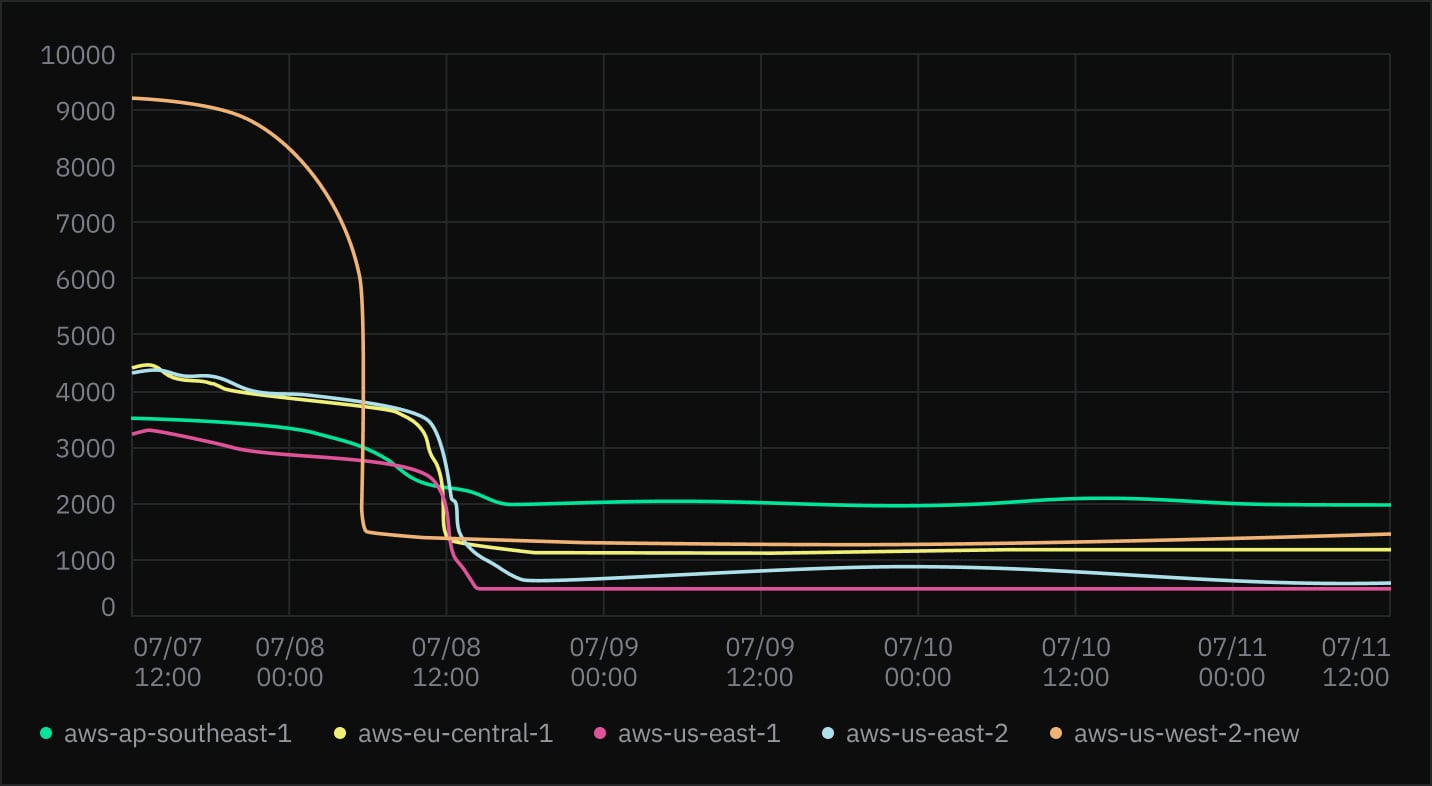
But wait! There’s more! Half a second is good, but it’s not the end: most notably, these speedy starts are the fastest in our us-east-2 region, and slowest in ap-southeast-1. We are in the middle of a herculean task–sort of like replacing the engine on an airplane without landing it–to divide our control plane up so that it can run closer to the computes it manages, at which point we expect the us-east-2 speeds to be the same everywhere else.
Related to this effort, autoscaling–currently in beta–will pair really nicely with the new model: rather than needing to maintain a bunch of pools for every compute size, we can maintain one pool of scalable computes, and then when a request for a new compute comes in, we pass the configuration and the size of the compute, and the compute becomes the right size. We can even make sure the compute starts lightly above a minimum, to ensure a speedy Postgres start up, before reducing the allocation (if necessary.) This is actually really close and should start to land in the next couple of weeks.
Not only is this (super!) cool, but it makes the problem of “how big should the pool be” much simpler. There’s also a bunch of smarts that we could implement to proactively change the size of the pools to more accurately and responsively address demand, but maybe autoscaling will afford us another opportunity to apply the good old “solve a hard problem (forecasting) by applying a different solution (dynamic resource allocation).”
There are, as always, lots of other changes, too: making Postgres faster at starting up, streamlining some of our internal protocols to remove unnecessary round trips, optimizing the management process inside of the compute, and maybe providing a way for compute instances to require less intervention from the control plane.
I’m skeptical that we’ll get to 50 milliseconds (but we’ll get close!), although I guessed wrong before.
Conclusions
This has been a great project, and I hope everyone is able to take advantage of it and use it to build great and efficient things with Neon!
Well, to be honest, I hope everyone quickly forgets that cold starts were ever a thing, and this post remains the only reminder that the amount of time it took for a sever to startup was ever a consideration: it is serverless, after all.